Servant plugin for SEO
Intro
I have website built with servant framework. And I need to add SEO for it. Here we go.
One day I started with a task where I had a choice:
- To make a solution that could be copy-pasted across several projects. It would be fast to implement but error-proned.
- Or to make a step back and to extend the framework with a new plugin.
Problem statement
I am talking about two handlers /robots.txt and /sitemap.xml useful in SEO optimisations in a project with servant as dependency. Unlike yesod, there are no such extensions in servant ecosystem.
So I had to add/modify the code by hand every time when I need to test some idea.
- Pros: it is quite fast to implement each time.
- Cons:
- maintenance cost: trigger on API modification should be installed to keep handlers up-to-date.
- could not be reused further.
Otherwise, to write plugin for servant.
- Pros:
- more compile-time checks.
- simpler usage.
- could be re-used heavily and even shared via OSS.
- Cons:
- harder to implement (i.e. type-level programming which I was not familiar with).
- as a consequence, more time should be spent on implementation.
Community opinion about servant is controversial (based on what I have heard). From user point of view it is simple. And the separation of API and handlers is great! Docs and tutorials are awesome! From development side, servant considered as type-level fancy stuff. That’s what I heard.
There were no hard issues with using servant. So I become curious. Is it really true about development side? The only way to find is to resolve my task this way and to share thoughts and findings with you.
I had only one hour per day (evenings, mostly). So I started.
Robots.txt
Robots.txt is plaintext file that could be statically or dynamically served from web server via /robots.txt handler. It gives instructions to robots what should be indexed and what should not.
User-agent: *
Disallow: /static
Sitemap: https://example.com/sitemap.xmlHere is an example of content I want to receive from API. It means that robots with any user-agent should not be allowed to index endpoints starting with /static. And sitemap is located by the following URL.
Robots specification is not limited by these commands. But for the start it would be enough. As a user, I want to specify Disallow as a keyword somewhere in API.
Sitemap.xml
Sitemap.xml is an XML file that could contain either list of URLs of pages that should be indexed by robots or list of nested sitemaps URLs if website index is large enough.
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.example.com</loc>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset> There is a /urlset/url list with an URL inside and some optional parameters. I want to use Frequency (i.e. /urlset/url/changefreq) and Priority (/urlset/url/priority) as keywords in API as well. And XML should be rendered somehow from API.
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>http://www.example.com/sitemap/1/sitemap.xml</loc>
</sitemap>
<sitemap>
<loc>http://www.example.com/sitemap/2/sitemap.xml</loc>
</sitemap>
</sitemapindex>There is a /sitemapindex/sitemap list with sitemap index. Each URL (//loc) from this index represents a single part of whole sitemap. If sitemap is large enough then sitemap index should be built instead. Each index location should contain no more than fifty thousands target locations (HTML page URLs). Sitemap specification contains more details.
Proposal for servant
In order to start the implementation I asked myself how final API should look like? What it should be like? And I came with something like:
-- ** Example API
type PublicAPI
= Get '[HTML] HomePage
:<|> ("blog" :> Frequency 'Always :> BlogAPI)
:<|> ("news" :> Capture ":newsurl" NewsUrl :> Get '[HTML] NewsPage)
:<|> ("search" :> QueryParam "q" SearchPattern :> Get '[HTML] SearchResultsPage)
:<|> ("about" :> Priority '(1,0) :> Get '[HTML] AboutPage)
:<|> "auth" :> ReqBody '[JSON] Login :> Post '[JSON] NoContent
type BlogAPI
= Capture ":blogurl" BlogUrl :> Get '[HTML] BlogPage
:<|> Capture ":blogurl" BlogUrl
:> ReqBody '[JSON] BlogComment
:> Post '[JSON, HTML] BlogPage
type ProtectedAPI = Disallow "admin" :> Get '[HTML] AdminPage
type StaticAPI = "cdn" :> Disallow "static" :> Raw
type API = StaticAPI :<|> ProtectedAPI :<|> PublicAPILooks like I need to encode Disallow, Frequency and Priority into API without any impact on serving.
-- ** Example app
startServer :: IO ()
startServer = do
Warp.runSettings Warp.defaultSettings
$ serveWithSeo website api server
where
website = "http://example.com"And I should find the way to derive both robots.txt and sitemap.xml with as less code as possible from user perspective. E.g. only one function serveWithSeo should be called.
Design and Implementation
Next step was to ask: what really should be implemented and how to achieve it? The only way to become comfortable with the task is to decompose it to degree where the each subtask from the tree would become transparent for you.
Functional requirements
I group all requirements on several components:
- Servant combinators.
Disallow,FrequencyandPriorityare the starting point in my journey. Robotsdata type. There should be the way to transform the final API into intermediateRobotsrepresentation.Sitemapdata type. The same as previous one but forSitemap.- UI part. User API should be automatically extended with sub-API for both
RobotsandSitemap. Handlers with default renderers should be provided from intermediate data types to target content types.
I was starting to notice how organically types drive me throughout the gathering of functional requirements.
Servant combinators
Disallowshould wrap the path piece of URL (i.e. symbol).Disallowshould not affectservant-serverfunctionality.Disallowshould be gathered toRobotsintermediate data type for each API branch.Disallowshould invalidateSitemapfor whole API branch if it is present in API branch.Frequencyshould be used with:>combinator.Frequencyshould have (on type level) one parameter with following available values (according to sitemap spec):never,yearly,monthly,weekly,daily,hourly,always.Frequencyshould not affectservant-serverfunctionality.Frequencyshould be gathered for each URL in contained API branch.- In case of several
Frequencyvalues in one API branch, the outer-most should be used, i.e. overwrite rule. Priorityshould be used with:>combinator.Priorityshould have (on type level) one parameter with a value representing priority according to sitemap spec, i.e. in range between 0.1 and 1.0.Priorityshould not affectservant-serverfunctionality.Priorityshould be gathered for each URL in contained API branch.- In case of several
Priorityvalues in one API branch, the outer-most should be used, i.e. overwrite rule.
Robots data type
I called it RobotsInfo.
RobotsInfoshould contain information about every API branch whereDisallowappeared, i.e. list of disallowed path pieces.RobotsInfoshould contain knowledge about sitemap presence in API (present or not).
Sitemap data type.
I called it SitemapInfo.
SitemapInfoshould contain list of sitemap entries (i.e.[SitemapEntry]).- Each
SitemapEntryshould represent particular API branch. SitemapEntryshould contain information about all pieces from which list of URLs could be constructed.SitemapEntryshould contain information about all query parameters from which list of URLs could be constructed.SitemapEntrymight containPriorityor not (optional parameter).SitemapEntrymight containFrequencyor not (optional parameter).SitemapInfoshould be automatically gathered once there isGet '[HTML] ain API present.- Rest methods or content-types should be ignored and no
SitemapInfoshould be created for such API branches. - It should be possible for User to implement how to retrieve a list of possible values for
userTypefromCapture' mods sym userType(we will discuss it later). - It should be possible for User to implement how to retrieve a list of possible values for
userTypefromQueryParam' mods sym userType(we will discuss it later). SitemapInfocould be splitted on sitemap index where every key from index should have reproducible set of corresponding URLs when its length is more than 50000.
UI: built-in API and handlers
- Provide the way to retrieve information from API to get
RobotsInfo. - Provide the way to retrieve information from API to get
SitemapInfo. - Provide the way to extend API with
/robots.txt. - Provide the way to extend API with
/sitemap.xml. - Provide the way to extend with
/sitemap/:sitemapIndex/sitemap.xml. - Provide default handler for Robots (i.e. rendering from
RobotsInfoto its textual representation). - Provide default handler for sitemap.
- Provide default handler for sitemap index.
- If sitemap URL list length is no more than 50000 then this list should be rendered.
- If sitemap URL list length is greater than 50000 then index list should be rendered.
- If sitemap URL list length is no more than 50000 then sitemap index should be empty (i.e. client should receive
HTTP 404 NOT FOUNDwhile querying/sitemap/:sitemapIndex/sitemap.xml). - If sitemap URL list length is greater than 50000 then sitemap index should be accessible (somehow).
I decided to choose at least one key per API branch. And if one particular branch will have more than 50000 URLs then split it on several keys/parts.
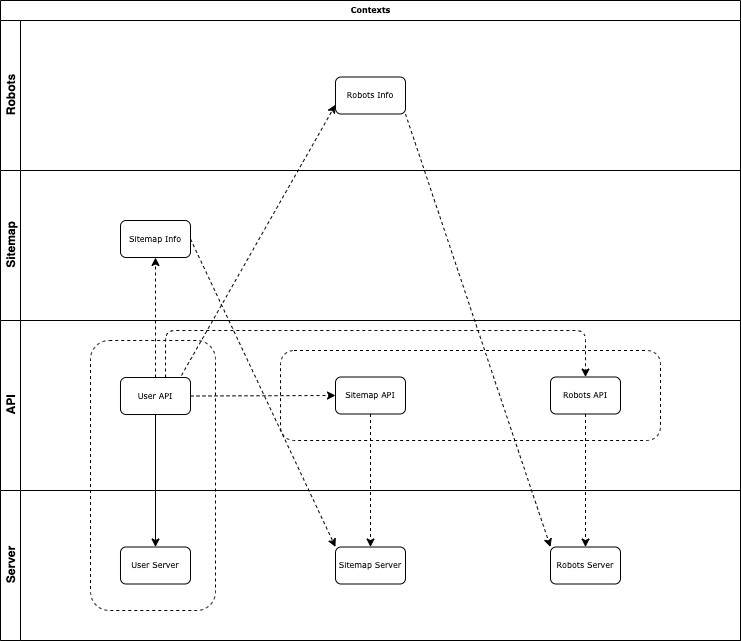
Diagram
There are several levels of context. For simplicity I draw them on this diagram.
Implementation details
There was one strange thing across the design. I started to see the pattern. How to implement these requirements without previous type-level experience. But I was not sure. I stepped back and read the brilliant book Thinking with Types by Sandy Maguire. I looked in servant-server, servant-swagger sources and Restricting servant query parameters by Alexander Vershilov as guidelines. These insights showed me how to deal with the task.
- Each servant combinator is inhabitant type.
RobotsInfoandSitemapInfoshould both beMonoidandSemigroupto be retrieved and combined altogether in their final representation.- Making a constraint (i.e. type class for inhabitant types and its instantiation) is a way to gather units. These units could be combined with each other.
Proxyis the way to retrieve information from type level to data level.- User-supplied values in
CaptureandQueryParamcould be handled with a separate type classes (25 and 26 requirements). User must implement instances for corresponding type classes for a function that looks likeMonadIO m => Proxy a -> app -> m [a]. Lists of possible values will be further propagated inCapture'andQueryParam'instances. - GHC itself was helpful throughout the way. It showed me which extensions should be included and brought the useful messages. The only time I felt that I am doing something really wrong was about
PolyKinds. When I needed types of different kinds GHC does not tell me anything about it. - GHC User Guide is an awesome reference!
Summary
- 4 inhabitant data types.
- 10 types.
- 5 type classes.
- 70 instances.
- 0 type families.
- 18 different language extensions.
- goal achieved.
Conclusion
I have heard a lot about Simple Haskell, Boring Haskell, Fancy Haskell. I realized that restrictions and limitations produced for good reasons: TTM, benefits vs. costs, risks and so on.
On the contrary, there are some awesome explanations from problem solving point of view. They lead to specific technologies or even “type-level magic” stuff.
These are different mindsets. They all share that problem have to be solved. Difference is in the way to solve the problems. Maybe different problems. Maybe higher-order problems. Maybe single task from long awaited todo-list.
One day you can find yourself in a situation when you have to deliver faster than usual. Another day there are no hard time boundaries and you feel relaxed. We are living in the endless uncertainty of estimations and expectations. We are living in chaos where nothing could be predicted.
Sometimes we know what should be done and we have to do the things we did before. Sometimes task feels like extremely new: new domain, interfaces, requirements, specs. Abstractions are quite good way to dealing with them. It is a single side of coin.
When you add team to consideration, situation could become even worse. In large projects it is absolutely normal that you spend on documenting/analysing/coding only 10% of business hours. Rest of time are about communications, mostly. Communications with business partners, with BA folks, with development team, with management, with QA team, with executives, with users.
I feel myself like I am simultaneously living in a few worlds. And it is hard to express the concerns to somebody because I have to understand what are the preconditions, what context is suitable for people I interact with, what goals they are pursuing, what agenda is on their tables. And it is impossible. In the village where I grew up, neighbours used to say: “Going to politics? - Good riddance!”
And I am starting to feel myself unhappy from the beginning of interaction. So the best solution for me in these situations is to remain silent. Unless, I am experiencing mentioned trade-offs by myself.
There is a force bigger than us. Nothing could stop it. We cannot resist it. We could only accept it and let it drive us all the way.
Since the beginning I struggled a lot, there were:
- health issues during hard self-isolation,
- surgical interventions,
- contacting with COVID-19,
- dealing with police as a consequence of contact,
- even hardware display issue on the laptop.
Despite all of that, the goal was achieved. It finally lets me go.
Results are available as a library:
- Github: https://github.com/swamp-agr/servant-seo
- Hackage: https://hackage.haskell.org/package/servant-seo
I encourage you to build useful website with servant and hundred of thousands pages and to be successfully indexed by robots!
If you have the notes to add or you see some issues in the spec/code, please contact me, e.g. on Github.
Thank you and have a good day!
Links (in order of appearance)
- Robots specification.
- Sitemap specification.
- Thinking with Types.
servant-server.servant-swagger.- Restricting servant query parameters.
- GHC User Guide.
- Simple Haskell.
- Boring Haskell.
- Fancy Haskell.
- Interview with Edward Kmett.
- https://github.com/swamp-agr/servant-seo.
- https://hackage.haskell.org/package/servant-seo.